A Multi-Agent Large Language Model Framework for Automated Q-Matrix Generation
AERA 2026 Annual Meeting
2026-04-01
Multi-Agent Framework
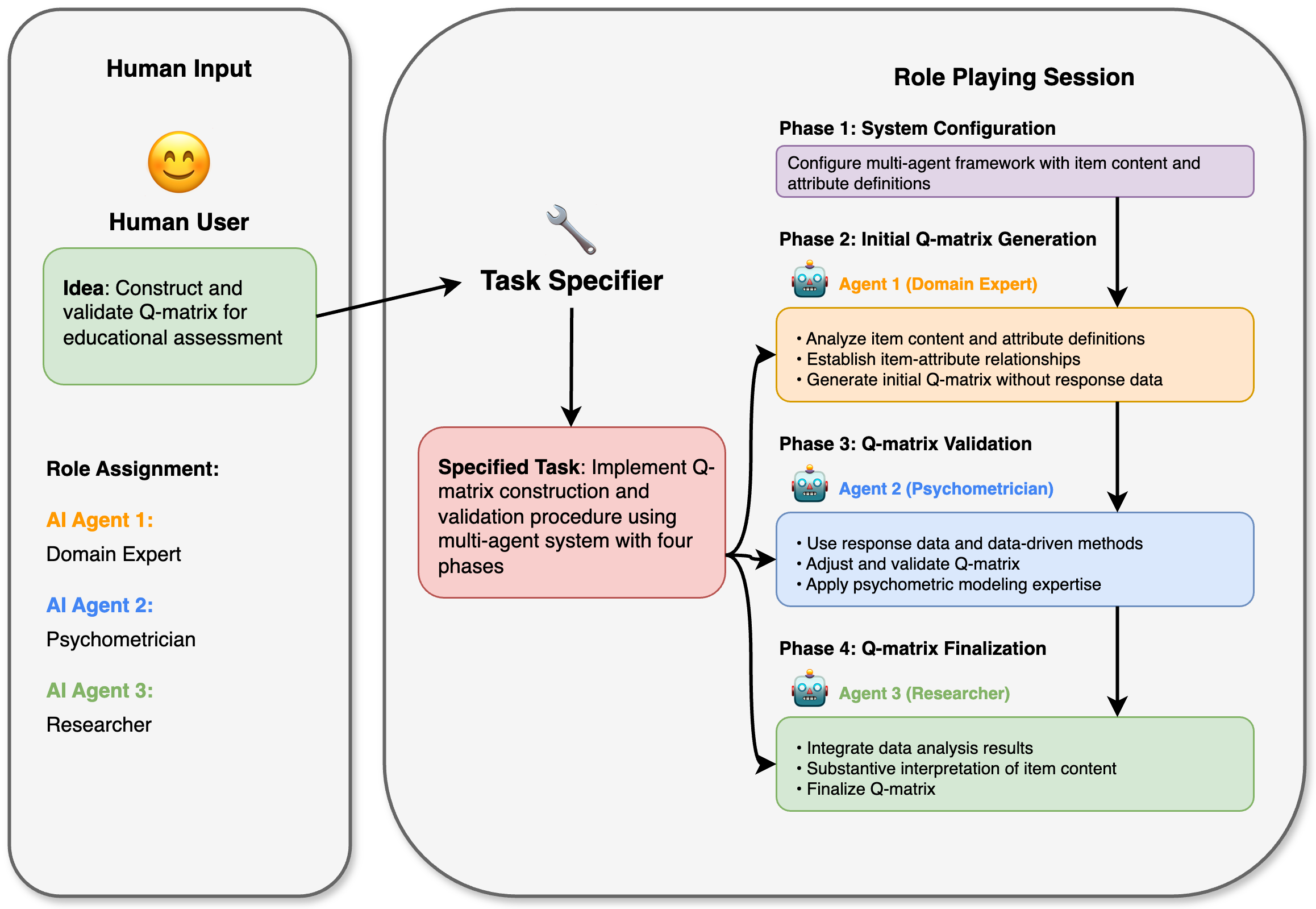
| Phase | Agent | Output |
|---|---|---|
| Generation | Domain Expert | \(Q_0\) from item content |
| Validation | Psychometrician | \(Q_1\) via GDINA/Qval |
| Finalization | Researcher | \(Q_{final}\) integrating \(Q_0\) + \(Q_1\) |
Study 1: Stability of Q-Matrices
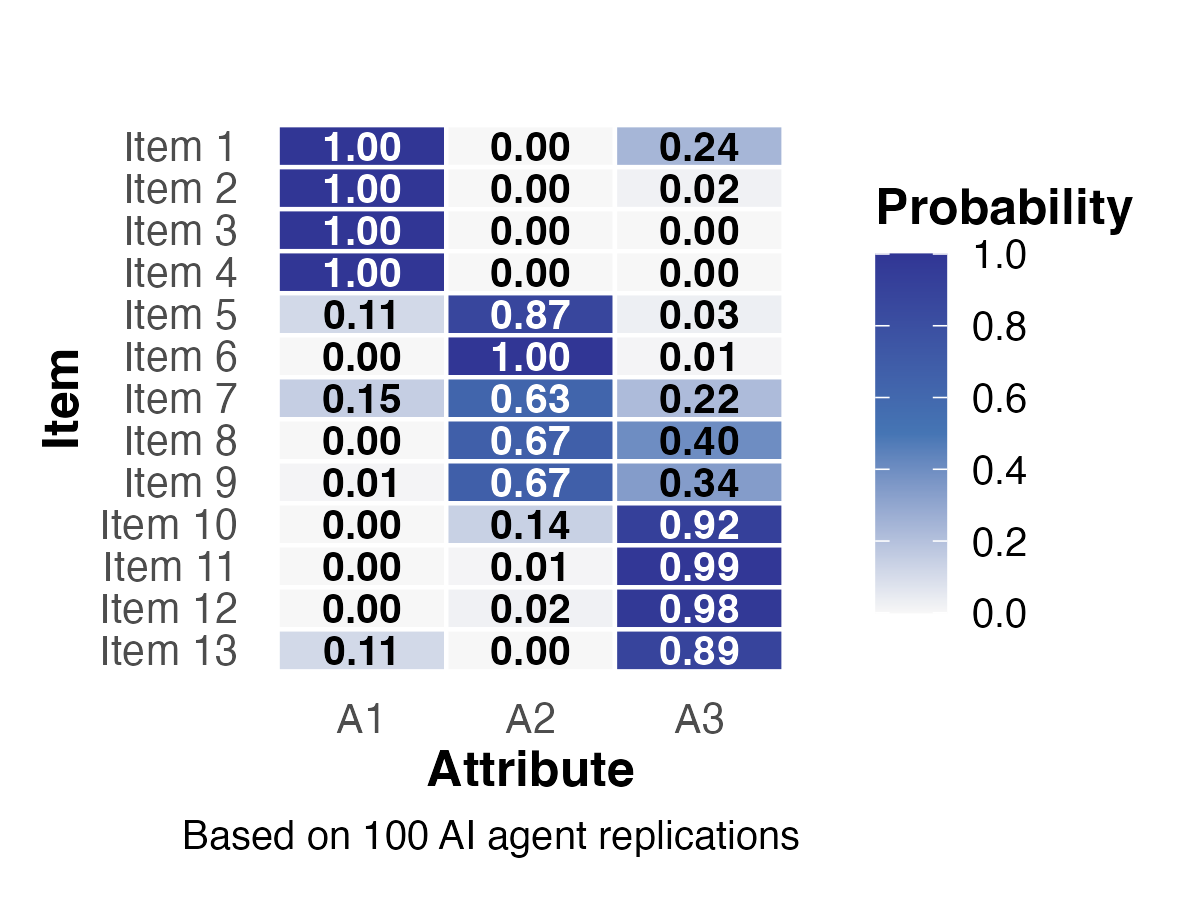
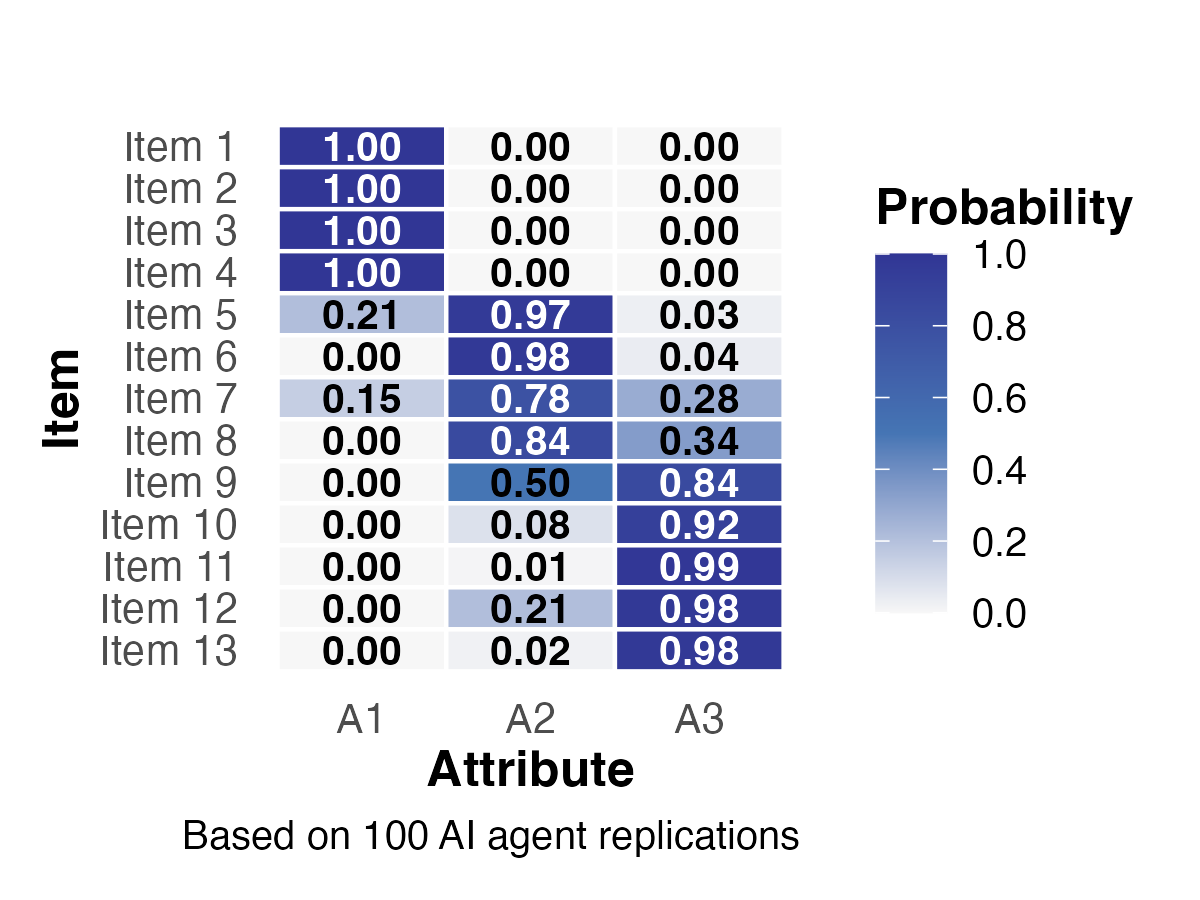
- Items 1–4 (A1) and 10–13 (A3): high certainty (\(p \approx 1.0\))
- Items 7–9 (A2): greater uncertainty, mixed patterns
- Validated Q-matrices showed reduced variability after data-driven validation
Study 1: Final Q-Matrix Results
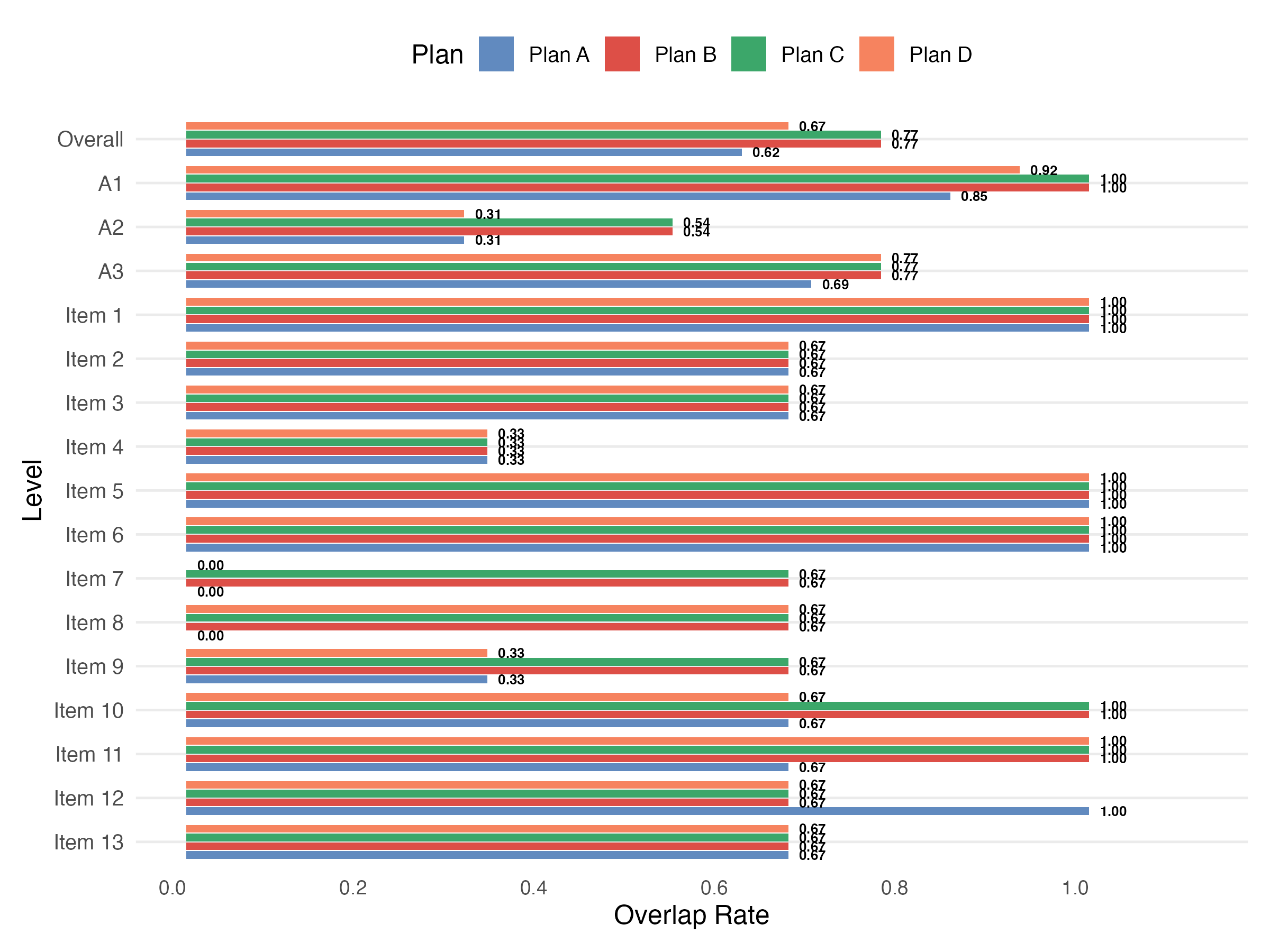
- Plans B, C (OR = 0.77) > Plan D (0.67) > Plan A (0.62)
- A1 (public performance): consistently highest overlap across all plans
- A2 (close scrutiny): consistently lowest — ambiguous construct boundaries
- Item 4 had lowest item-level OR (0.33) across all plans
- Items 7–9 showed inconsistent patterns across finalization strategies
Study 2: Stability of Q-Matrices
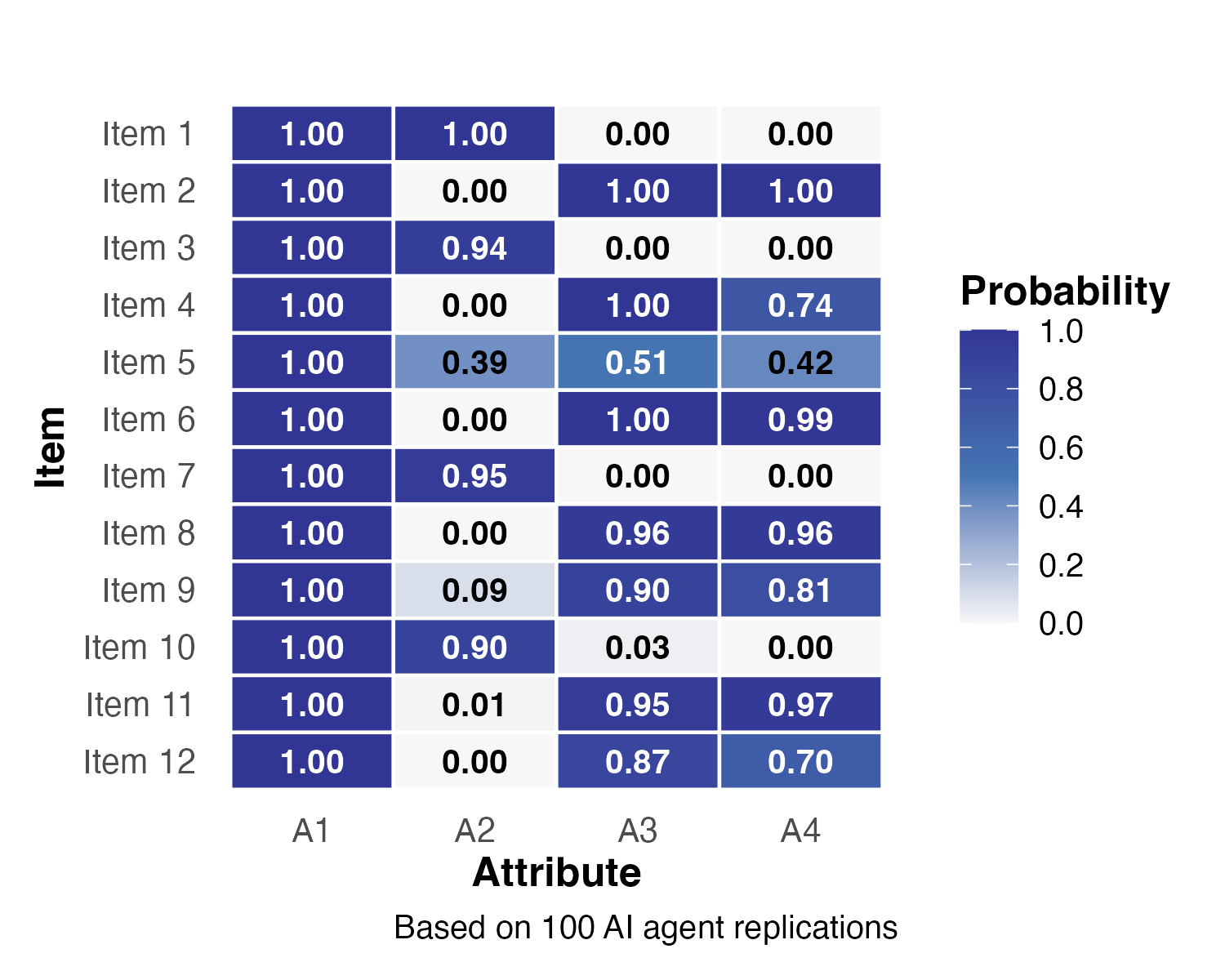
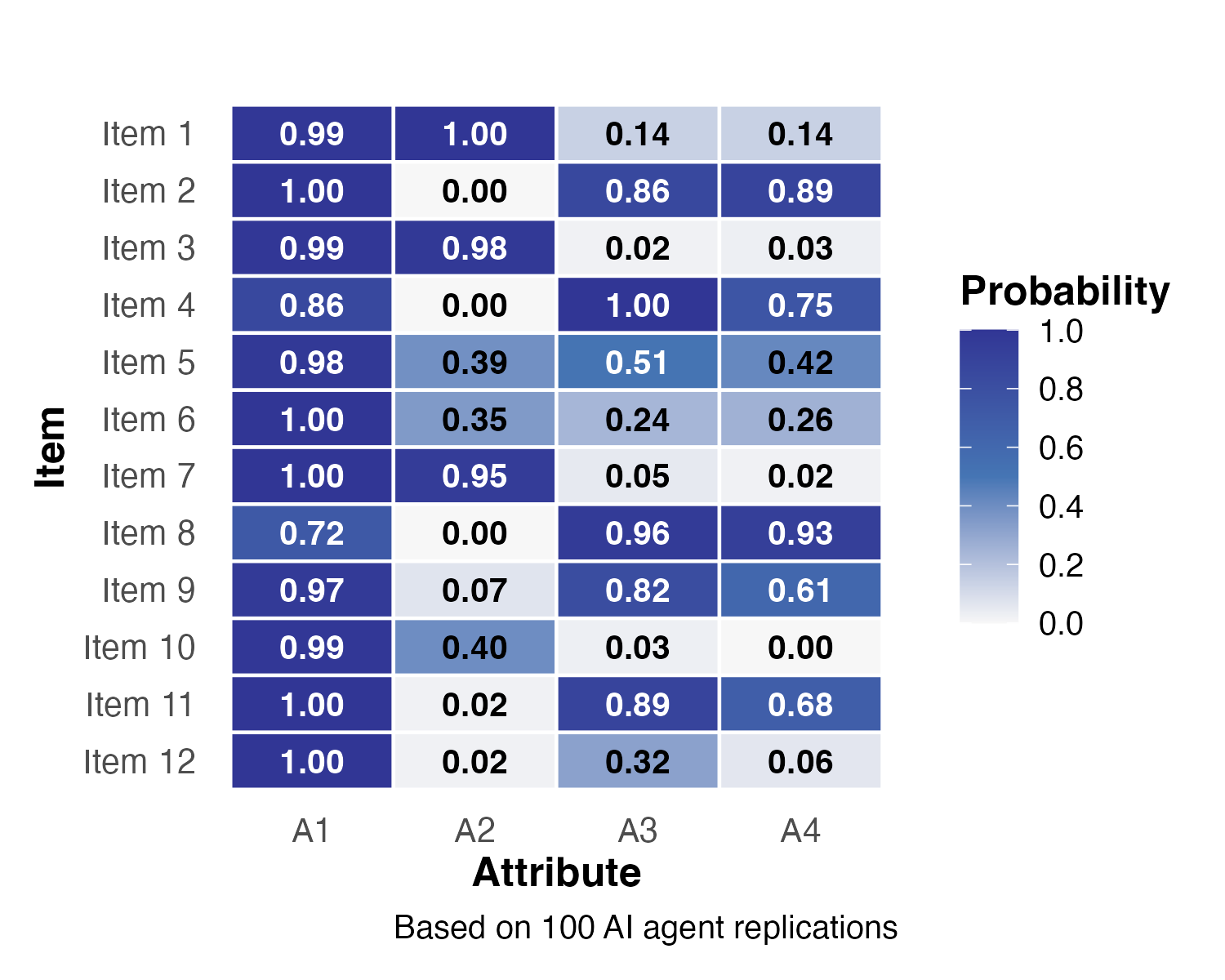
- A1 assigned with perfect certainty (\(p = 1.0\)) across all items
- Items 5 and 12 showed notable shifts after validation
- Item 12: A3 probability dropped from 0.87 to 0.32; A4 from 0.70 to 0.06
Study 2: Final Q-Matrix Results
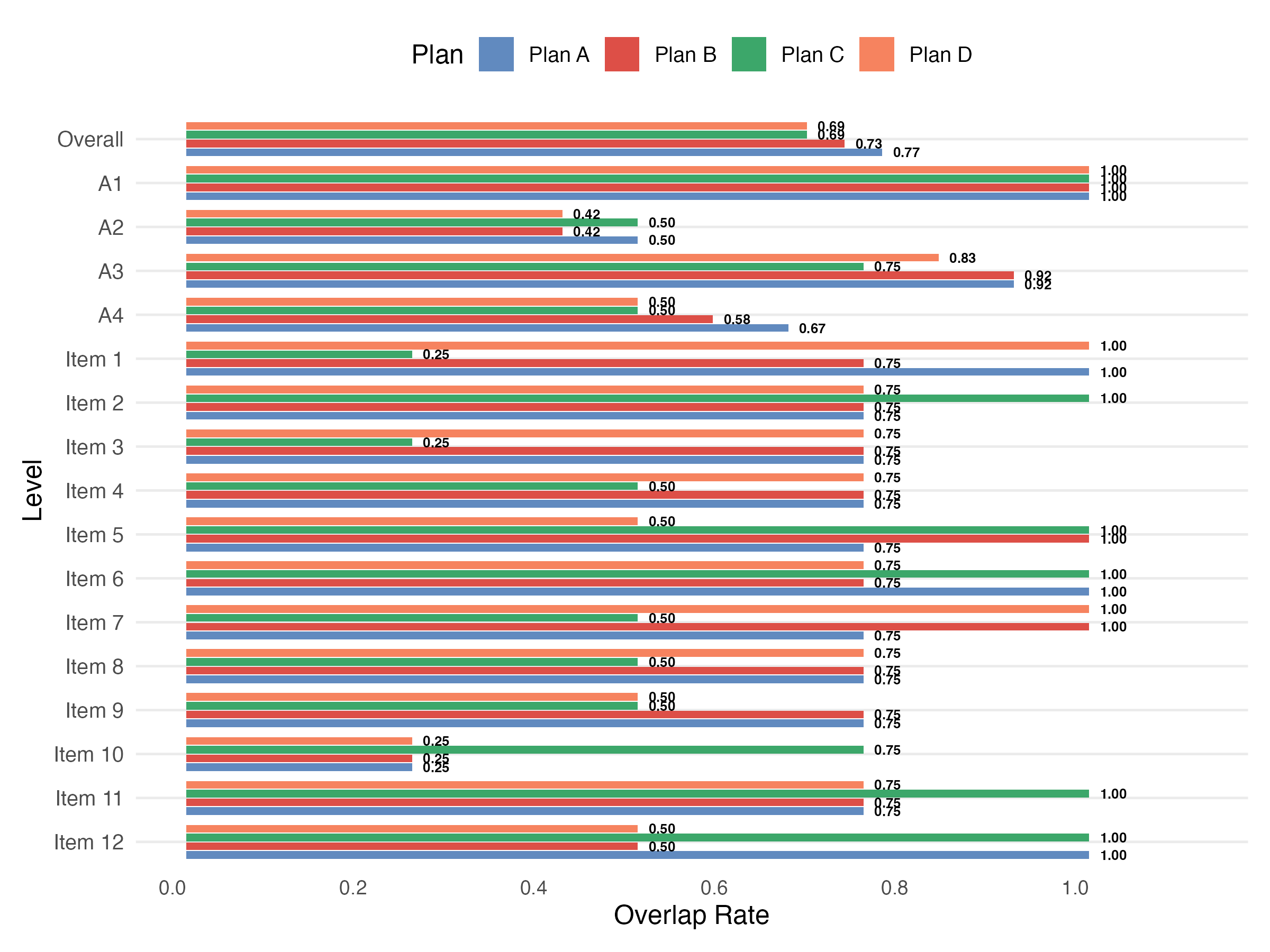
- Plan A produced the highest overall OR (0.77)
- Plans C and D yielded the lowest (0.69)
- A1 (basic subtraction): perfect overlap (1.00) across all plans
- A2 (simplifying): most challenging attribute to classify
- Item 10 had lowest item-level OR (0.25) across all plans
- Opposite pattern from Study 1 — optimal strategy depends on construct nature
